Lookback Windows are Critical for Successful Models with Behavioral Data
In a traditional brick and mortar store, there are clear operating hours. Most stores are closed for a significant number of hours each day, during which the staff can perform backend tasks (counting inventory, restocking, redesigning displays).
But in a digital ecosystem, there is no such downtime. The digital ecosystem is continually evolving, and users are constantly taking action — viewing and clicking on ads, browsing different topics and items, adding some of those items to their shopping carts, navigating away, making purchases.
The good news is digital behavior is the most valuable signal in your marketing technology stack. The bad news is finding the signal in this behavioral data poses a number of challenges, not least the one it introduces for Data Engineers, who rely on behavioral data to build predictive models. Essentially, when Engineers look to sample a dataset, it is non-trivial to ensure each individual has similar amounts of data since new data is generated and added to the dataset at every moment.
The question, then, is how to build effective models in this constantly evolving ecosystem.
Let’s say a data science organization is trying to build a model that helps predict whether a visitor is likely to make a purchase. The first step is to collect data to train the model. Your first instinct might be to simply query all visitor activity within a set period of time — say, a month — then use this data to train your model, and then send it to production. In fact, this is the approach that most data scientists use. They sample a period of data, feed it into a few contender models, select their highest-performing model, and send it to production.
Then they spend hours, days, and weeks troubleshooting the reasons why their productionized model pales in comparison to the one they originally built and tested.
The problem is that in training their model with all of a visitor’s data within a given timeframe, they almost certainly included post-purchase user data.
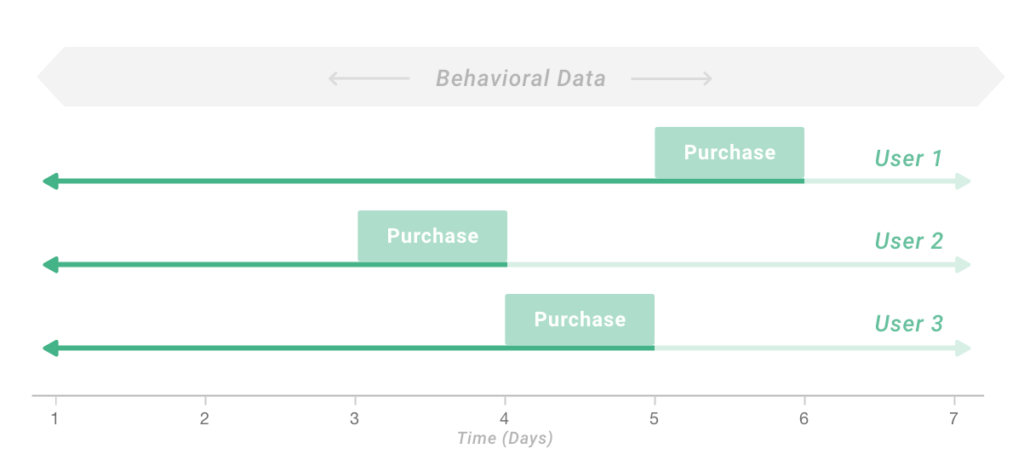
This is problematic when your model needs be able to use post-purchase behavior to predict actions for visitors that haven’t purchased yet. To take an extreme example, viewing the “thank you for your purchase” page might be a very strong predictor of purchasing intent, but it won’t be seen by visitors until after they make their purchase. Any post-purchase behavioral data that gets into your training data will pollute your model and lead it to make incorrect inferences. Once it goes into production, your model will no longer have access to the post-purchase activity that correlated so strongly to purchases, because that activity hasn’t happened yet.
The Solution
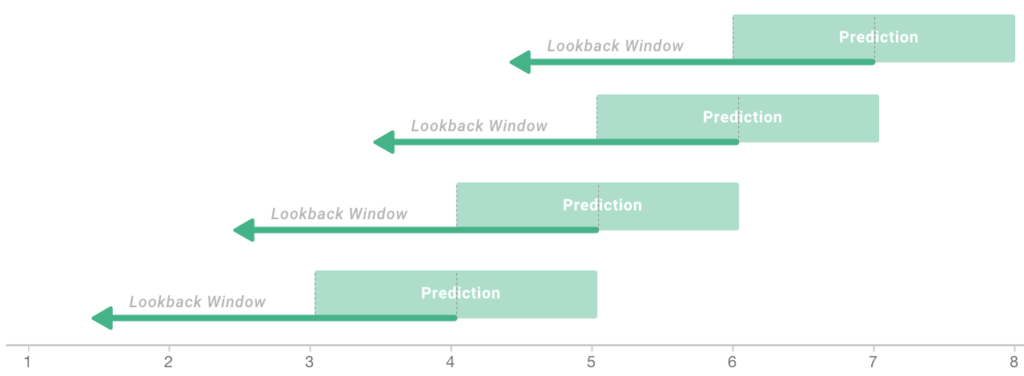
Syntasa has been thinking about, and devising solutions for, problems like these for many years. We have developed a framework for dealing with continually incoming data that has successfully stood the test of time. Our framework relies on the concept of a sliding window, which mimics the production environment by excluding data that a production environment wouldn’t contain.
The heart of the problem is that visitors can make a purchase at any point in a given window of time — Day 3, Day 15, Day 23, etc. In order to address this problem, we need to view the data from the perspective of each individual visitor’s experience using a sliding window, rather than using a generalized time frame for all visitors.
Syntasa’s approach reconciles the behavioral data for each visitor on your list of purchasers and filters for actions that happened before the purchase and within a specified lookback window. This builds an accurate history of the actions that led to each visitor’s purchase, and ensures that only pre-puchase activity is used to create features to train your model.

A sliding window framework does a much better job of approximating production environments. As we’ve established, in the real world your model will only have access to the data that happened before the purchase. Therefore, training your model using a sliding window approach ensures that the quality of its results don’t rely on data that won’t be available in a production environment.
This more personalized approach also allows you to use a uniform time period when building users’ histories. Instead of the length of a user’s history depending on where in your time period their purchase occurred, every user history will contain the same number of days of activity. So, instead of having 17 days of activity for the user who made a purchase on day 17, and 26 days of activity for the user who made a purchase on day 26, you will have the same number of days for both of them. Exactly how many days of data you need for an accurate model will vary by use case.
One thing that is mentioned briefly in this blog post is how you might choose which model is performing the best out of your contender models. In an upcoming post, we’ll talk about some evaluation metrics that might be useful for different use cases, and how to use those metrics to choose your best model.